
Computing Hardware
The CRC provides different hardware types to target different computing use cases. These hardware profiles are grouped together under a common cluster name and are further divided into partitions to highlight differences in the architecture or usage modes.
| Cluster Acronym | Full Form of Acronym | Description of Use Cases |
| mpi | Message Passing Interface | For tightly coupled parallel codes that use the Message Passing Interface APIs for distributing computation across multiple nodes, each with its own memory space |
| htc | High Throughput Computing | For genomics and other health sciences-related workflows that can run on a single node |
| smp | Shared Memory Processing | For jobs that can run on a single node where the CPU cores share a common memory space |
| gpu | Graphics Processing Unit | For AI/ML applications and physics-based simulation codes that had been written to take advantage of accelerated computing on GPU cores |
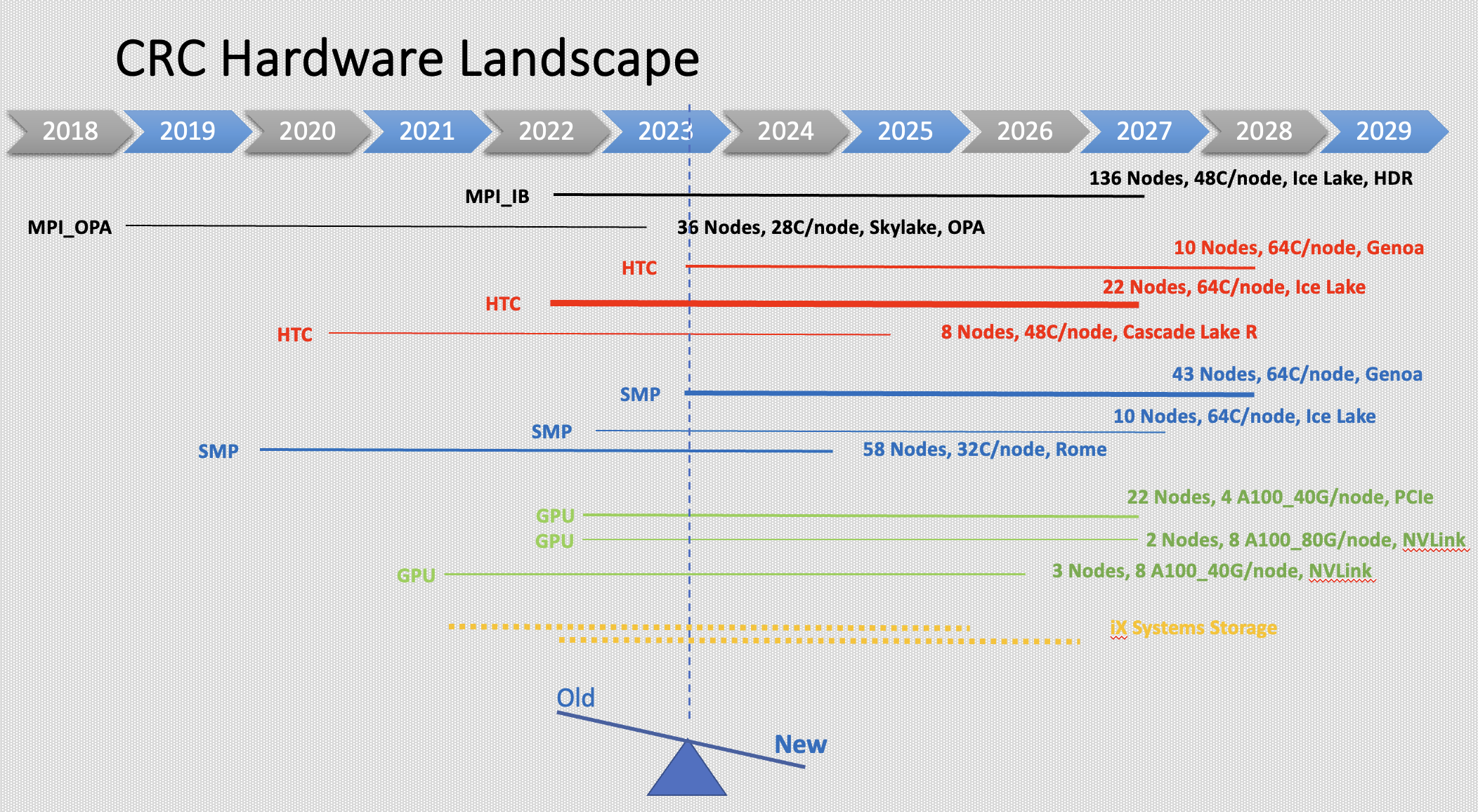
Below, you will find the hardware specifications for each cluster and the partitions that compose it:
MPI Cluster
The MPI nodes are for tightly-coupled codes that are parallelized using the Message Passing Interface (MPI) and benefit from low-latency communication through an Infiniband (HDR200) or Omni-Path (OPA) network. Your job must request a minimum of 2 nodes.
| Partition | Architecture | Nodes | Cores/Node | Mem/Node | Mem/Core | Scratch | Network | Nodes |
|---|---|---|---|---|---|---|---|---|
| mpi | Intel Xeon Gold 6342 (Ice Lake) | 136 | 48 | 512 GB | 10.6 GB | 1.6 TB NVMe | HDR200; 10GbE | mpi-n[0-135] |
| opa-high-mem | Intel Xeon Gold 6132 (Skylake) | 36 | 28 | 192 GB | 6.8 GB | 500 TB SSD | OPA; 10GbE | opa-n[96-131] |
HTC Cluster
These nodes are designed for High Throughput Computing workflows such as gene sequence analysis, neuroimaging data processing, and other data-intensive analytics.
| Partition | Architecture | --constraint | Nodes | Cores/Node | Mem/Node | Mem/Core | Scratch | Network | Nodes |
|---|---|---|---|---|---|---|---|---|---|
| htc | AMD EPYC 9374F (Genoa) | amd, genoa | 20 | 64 | 768 GB | 12 GB | 3.2 TB NVMe | 10GbE | htc-n[50-69] |
| Intel Xeon Platinum 8352Y (Ice Lake) | intel, ice_lake | 18 | 64 | 512 GB | 8 GB | 2 TB NVMe | 10GbE | htc-n[32-49] | |
| Intel Xeon Platinum 8352Y (Ice Lake) | intel, ice_lake | 4 | 64 | 1 TB | 16 GB | 2 TB NVMe | 10GbE | htc-1024-n[0-3] | |
| Intel Xeon Gold 6248R (Cascade Lake) | intel, cascade_lake | 8 | 48 | 768 GB | 16 GB | 960 GB SSD | 10GbE | htc-n[24-31] |
SMP Cluster
The SMP nodes are appropriate for programs that are parallelized using the shared memory framework. These nodes are similar to your laptop but with more memory and more CPU cores. To request a particular feature (such as an Intel host CPU), add the following directive to your job script:
#SBATCH --constraint=intel
Multiple features can be requested by providing a comma-separated list (without intervening spaces):
#SBATCH --constraint=amd,genoa
| Partition | Architecture | --constraint | Nodes | Cores/Node | Mem/Node | Mem/Core | Scratch | Network | Nodes |
|---|---|---|---|---|---|---|---|---|---|
| smp | AMD EPYC 9374F (Genoa) | amd, genoa | 43 | 64 | 768 GB | 12 GB | 3.2 TB NVMe | 10GbE | smp-n[214-256] |
| AMD EPYC 7302 (Rome) | amd, rome | 55 | 32 | 256 GB | 8 GB | 1 TB SSD | 10GbE | smp-n[156-210] | |
| Retired |
|||||||||
| high-mem | Intel Xeon Platinum 8352Y (Ice Lake) | intel, ice_lake | 8 | 64 | 1 TB | 16 GB | 10 TB NVMe | 10GbE | smp-1024-n[1-8] |
| Intel Xeon Platinum 8352Y (Ice Lake) | intel, ice_lake | 2 | 64 | 2 TB | 32 GB | 10 TB NVMe | 10GbE | smp-2048-n[0-1] | |
| AMD EPYC 7351 (Naples) | amd, naples | 1 | 32 | 1 TB | 32 GB | 1 TB NVMe | 10GbE | smp-1024-n0 | |
| Intel Xeon E7-8870v4 (Broadwell) | intel, broadwell | 4 | 80 | 3 TB | 38 GB | 5 TB SSD | 10GbE | smp-3072-n[0-3] |
GPU Cluster
The GPU nodes are targeted for applications specifically written to take advantage of the inherent parallelism and massive amounts of cores in the architecture. We name the partitions after the GPU type along with a suffix as needed to indicate usage mode. The partition parameters are described below.
- Partition: l40s. This partition is appropriate for AI, simulations, 3D modeling workloads that require up to 4x gpus on a single node and rely on single or mixed precision operations (Note: This partition does not support double precision - FP64).
- Partition: a100. This is the default partition in the gpu cluster and is appropriate for workflows that require up to 4x gpus on a single node. To request a particular feature (such as an Intel host CPU), add the following directive to your job script:
#SBATCH --constraint=intel
Multiple features can be specified in a comma-separated string.
- Partition: a100_multi. This partition supports multi-node GPU workflows. Your job must request a minimum of 2 nodes and 4 GPUs on each node.
- Partition: a100_nvlink. This partition supports multi-GPU computation on an Nvidia HGX platform with 8x A100 that are tightly coupled through an NVLink switch. To request a particular feature (such as an A100 with 80GB of GPU memory), add the the following directive to your job script:
#SBATCH --constraint=80g
- Partition: gtx1080. Older gaming GPUs with 11GB of memory
- Partition: v100. Tesla V100 GPUs with 32GB of HBM2 memory
- Partition: power9. Four nodes of IBM Power System AC922: dual-socket Power9 (16C, 2.7GHz base, 3.3GHz turbo) with a direct NVLink to 4x V100 GPUs. Code must be compiled for the Power9 platform in order to work.
| Partition | Nodes | GPU Type | GPU/Node | --constraint | Host Architecture | Core/Node | Max Core/GPU | Mem/Node | Mem/Core | Scratch | Network | Nodes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| l40s | 20 | L40S 48GB | 4 | l40s,48g,intel | Intel Xeon Platinum 8462Y+ | 64 | 16 | 512 GB | 8 GB | 7 TB NVMe | 10GbE | gpu-n[55-74] |
| a100 | 10 | A100 40GB PCIe | 4 | a100,40g,amd | AMD EPYC 7742 (Rome) | 64 | 16 | 512 GB | 8 GB | 2 TB NVMe | HDR200; 10GbE | gpu-n[35-44] |
| 2 | A100 40GB PCIe | 4 | a100,40g,intel | Intel Xeon Gold 5220R (Cascade Lake) | 48 | 12 | 384 GB | 8 GB | 1 TB NVMe | 10GbE | gpu-n[33-34] | |
| a100_multi | 10 | A100 40GB PCIe | 4 | a100,40g,amd | AMD EPYC 7742 (Rome) | 64 | 16 | 512 GB | 8 GB | 2 TB NVMe | HDR200; 10GbE | gpu-n[45-54] |
| a100_nvlink | 2 | A100 80GB SXM | 8 | a100,80g,amd | AMD EPYC 7742 (Rome) | 128 | 16 | 1 TB | 8 GB | 2 TB NVMe | HDR200; 10GbE | gpu-n[31-32] |
| 3 | A100 40GB SXM | 8 | a100,40g,amd | AMD EPYC 7742 (Rome) | 128 | 16 | 1 TB | 8 GB | 12 TB NVMe | HDR200; 10GbE | gpu-n[28-30] | |
| gtx1080 | 9 | GTX 1080 Ti 11GB | 4 | Intel Xeon Silver 4112 (Skylake) | 8 | 2 | 96 GB | 12 GB | 480 GB SSD | 10GbE | gpu-n[17-25] | |
| power9 | 4 | V100 32GB SXM | 4 | IBM Power System AC922 | 128 threads | 16 | 512 GB | 4 GB | 1 TB SSD | HDR100; 10GbE | ppc-n[0-4] |
Portal: Viz Nodes
Users should open the Web URL in a browser to access a Linux Desktop. The Web URL will resolve to a backend hostname in a round-robin fashion to help balance usage.
| Web URL | backend hostname | GPU Type | # GPUs | Host Architecture | Cores | Mem | Mem/Core | Scratch | Network |
|---|---|---|---|---|---|---|---|---|---|
| https://viz.crc.pitt.edu | viz-n0.crc.pitt.edu | GTX 1080 8GB | 2 | Intel Xeon E5-2680v4 (Broadwell) | 28 | 256 GB | 9.1 GB | 1.6 TB SSD | 10GbE |
| viz-n1.crc.pitt.edu | RTX 2080 Ti 11GB | 2 | Intel Xeon Gold 6226 (Cascade Lake) | 24 | 192 GB | 8 GB | 1.9 TB SSD | 10GbE |
Portal: Login Nodes
Users should use the hostname as the remote host target of an ssh session. The hostname will resolve to a backend hostname in a round-robin fashion to help balance usage.
| hostname | backend hostname | Architecture | Cores/Node | Mem | Mem/Core | OS Drive | Network |
|---|---|---|---|---|---|---|---|
| h2p.crc.pitt.edu | login0.crc.pitt.edu | Intel Xeon Gold 6326 (Ice Lake) | 32 | 256 GB | 8 GB | 2x 480 GB NVMe (RAID 1) | 25GbE |
| login1.crc.pitt.edu | Intel Xeon Gold 6326 (Ice Lake) | 32 | 256 GB | 8 GB | 2x 480 GB NVMe (RAID 1) | 25GbE | |
| htc.crc.pitt.edu | login3.crc.pitt.edu | Intel Xeon Gold 6326 (Ice Lake) | 32 | 256 GB | 8 GB | 2x 480 GB NVMe (RAID 1) | 25GbE |