
Parsing human rights via machine learning

Are human rights around the world improving? It’s a big question. Have decades of attention from governments and non-governmental organizations such as Amnesty International had any effect?
Pitt political science professor Michael Colaresi sought to answer that question by analyzing language in U.S. State Department human rights reports. Colaresi, William S. Dietrich II Chair of political science (who teaches a course on coding and computational social science) worked with post-doc Baekkwan Park to develop a machine learning model to parse millions of words of text, a task which otherwise would require countless human hours. Pitt CRC provided computational power for the project.
The model avoids simplistic overall judgments of good or bad. Colaresi explains with an analogy to movie reviews. “When you talk about a movie, you don’t just say it was good or bad. You talk about the reasons that your judgment is based on – maybe the acting was good, but the plot was terrible, or your favorite supporting actor was great, but the leading man was lousy. Annual human rights reports began in 1977 by a group, such as the US State Department, writing about their judgements. Later, researchers, reading those reports, assigned countries a numerical score on a ‘political terror scale’ of the right to not be beaten, jailed, or killed for political activity. With access to decades of data that scale, or any fixed scale, looks incomplete It doesn’t capture the increasing range of reasons and rights that are being judged over time.”
Park describes the machine learning model. “We parsed thousands of documents to analyze semantic relationships between words, which is very memory intensive. The algorithm we used is cutting-edge but slow. Parsing 2,500 mid-size documents took six days without CRC resources, and we parsed a lot more than that, working with 39 years of reports covering 85-152 countries in any given year. Processing times and memory requirements varied significantly between documents, and the CRC gave us efficient load balancing and resource management, which were crucial.” Park says the support of CRC research assistant professor Barry Moore II was “indispensable.”
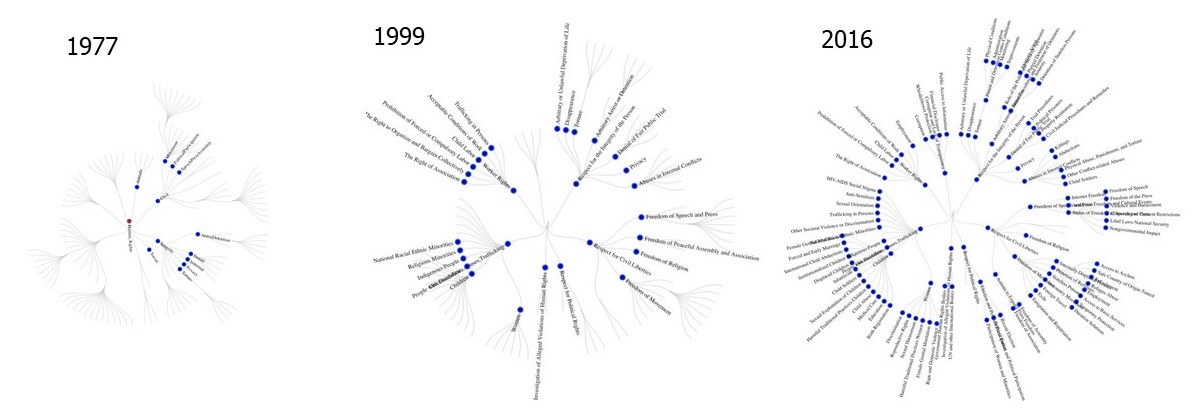
Colaresi and Park created a framework of metadata based on section titles in the reports. The 1977 report contained three sections. The 2016 report comprises 117 sections, which include categories such as the treatment of women in civil war and rights of the disabled.
Colaresi and Park organized paragraphs into categories and subsections (see the graph below). They trained their models on 2015 and 2016 reports to recognize when specific rights were being judged (and when they appeared to be ignored), then analyzed reports from 1977 to 2014 to evaluate the systematic changes in the rights showing up in the text over time.Their overall conclusion is that newer reports don’t show more negative judgments attached to the same words used in older reports. Similar violations are not necessarily getting worse, but newer reports include more types of potential violations. As definitions expand of what constitutes a human right, overall human rights may appear to decline (or improve) purely based on what is being judged, not necessarily government behavior around the world. With new measures of what is being judged, it is possible to make more valid and precise comparisons between countries and across spans of time.
Below::Three forest graphs illustrate the the expansion of categories of human rights (branches) and specific human rights (leaves) :from 1977 through 2016.
Contact:
Brian Connelly
Pitt Center for Research Computing
bgc14@pitt.edu